随着ChatGPT的成功问世,NLP正式迎来了新纪元。各大厂商为了提高自己的竞争力,也相继开源了自己的大模型。但是这些大模型在某些特定领域中所表现出的效果并不一定能达到用户的预期。为了使得模型在特定领域或下游任务中,能更好地满足用户和业务的需求,如何对开源大模型进行高效地微调成为了一项值得研究的工作。
目前,常见的微调方案包括两种:全量参数微调和参数高效微调。
全量参数微调(Full Parameter Fine-Tuning):直接对预训练模型所有参数进行微调,这种方法所需要消耗的资源和算力很大。
参数高效微调(Parameter-Efficient Fine-Tuning,PEFT):只微调少量(或额外的)模型参数,便可达到与全量微调相当的效果,从而大大降低了计算和存储成本。
常见的PEFT方法包括LoRA、Prefix Tuning、Prompt Tuning、P-Tuning等。
LoRA:Low-Rank Adaptation
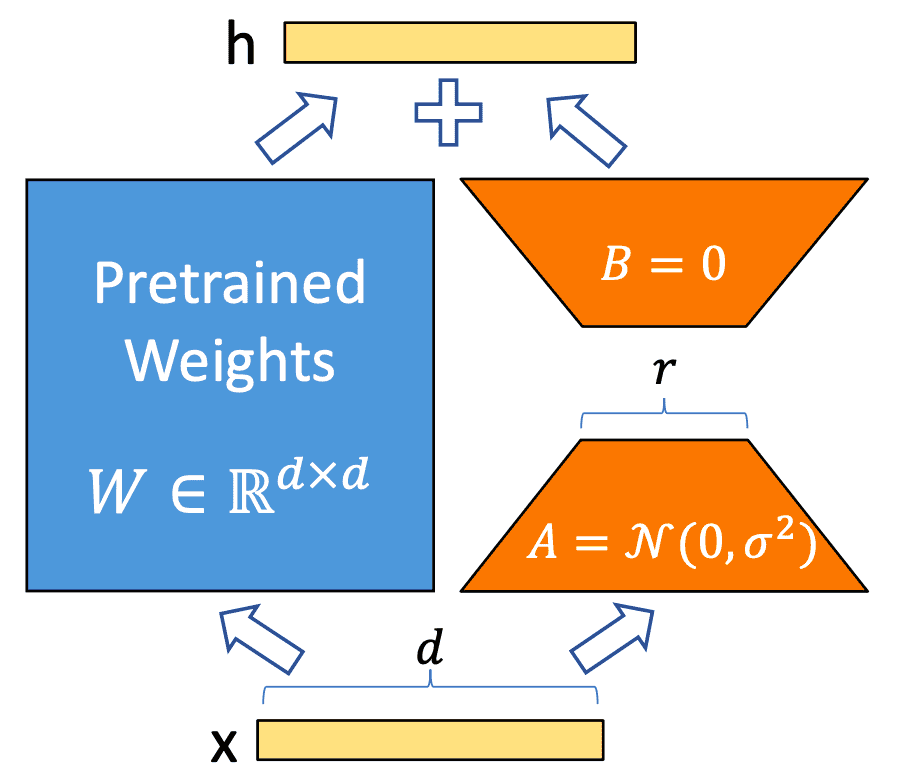
LoRA的主要思想:
在原始的预训练权重$W_0∈R^{d×k}$一旁增加一个旁路$\Delta W$(LoRA要微调的部分,上图右侧部分),旁路包括$B∈R^{d×r}$矩阵和$A∈R^{r×k}$矩阵。
$$W = W_0 + \Delta W = W_0 + BA$$
在微调阶段,固定住原始预训练的参数($W_0$不更新),只更新降维矩阵A和升维矩阵B(先降维再升维的优化策略和ALBERT有些类似),通过微调附加的A、B矩阵,来使得模型更适用于特定领域或者下游任务。在初始化时,用随机高斯分布初始化A,用0矩阵初始化B,保证训练开始时权重矩阵$\Delta W$依然是0矩阵。
$$h = Wx = W_0x + \Delta Wx = W_0x + BAx$$
在推理过程中,只需要计算$W = W_0 + \Delta W$即可。
$$h= W_0x + BAx = W_0x + \Delta Wx =(W_0+ \Delta W) x$$
参考:
[1] PEFT: State-of-the-art Parameter-Efficient Fine-Tuning.
[2] LoRA: Low-Rank Adaptation of Large Language Models
[3] LoRA:大模型轻量级微调
[4] 大模型微调总结

